国外有一项针对800多家企业的CIO采访调查,得出的结论:
“企业云生态系统规模和复杂性伴随着日益扩大的需求,与IT 资源管理能力之间的差距越来越大。”
被采访的很多人对自己企业IT团队有效支持业务的能力感到担忧,因为传统的监控解决方案使他们的团队淹没在数据和警报中。
就数据来看,平均而言团队每天从他们的监控和管理工具中收到近3000个告警。面对如此多的告警,IT团队平均要花费15%的可用时间来识别哪些告警需要关注,哪些告警是不相关的,这使得企业每年平均花费150万美元以上的管理费用在这些事情上。
这可是个很严重的问题。
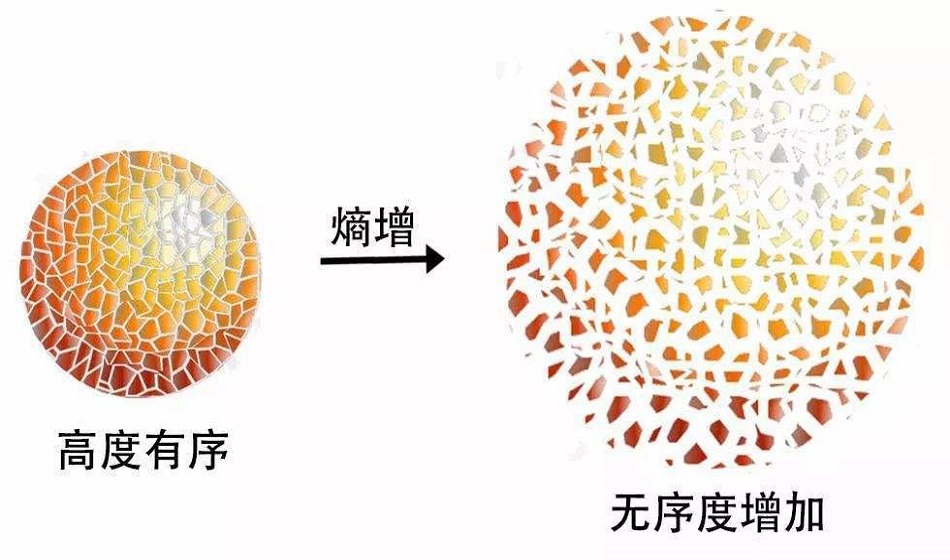
让我们从熵开始说起
熵是一个科学概念,也是一种可测量的物理特性,最常与无序、随机或不确定状态相关联。这个术语和概念被用于不同的领域,从最初被认可的经典热力学,到统计物理学中对自然的微观描述,再到信息论的原理。
熵亦被用于计算一个系统中的失序现象,也就是计算该系统混乱的程度。熵是一个描述系统状态的函数,但是经常用熵的参考值和变化量进行分析比较,在不同的学科中也有引申出的更为具体的定义,是各领域十分重要的参量。

(图片来自:中文百科)
在热力学领域熵产生的原因,可以理解为能量转换的时候,大部分能量会转换成预先设定的状态,比如热能变成机械能、电能变成光能。但是,还有一部分能量会生成新的状态,这部分能量就可以看作是熵。总之,能量转换会创造出新的状态,熵就是进入这些状态的能量。
社会进步都是处理熵的过程
回顾下人类发展的历史轨迹不难发现,人类社会的重大变革都是伴随着技术的进步,新技术使人类获得了新的力量(包括新的知识)用于解决原有的熵问题。

石器加工技术
人类学会了以石头为原料,加工成各种工具用来捕猎或打开坚硬的食物外壳,大大丰富了食物的选择,最终使多数人拥有了定居生活,并逐渐进入了氏族社会。

农耕技术

冶炼锻造技术
人类掌握了对金属的冶炼锻造技术生产出更好的农具,使得种植效率大幅提升到可以养活更多人口,加上新的武器大规模生产出来,使得领主间的战争进入常态化,随着一些氏族被征服或消灭,逐渐建立起一个庞大的封建王国。

造纸术和印刷术
人类的文化记载第一次可以廉价地大规模传播,包括宗教的思想的快速扩张,到后期文艺复兴运动的兴起,人类精神文明发展进入一个新的阶段。
热能、电能、核能技术
伟大的工业革命始于人类能够制造蒸汽机来利用热能,它的出现令生产力水平呈现指数级提升,并使社会出现大规模的分工和交换。而后的电能、核能的利用,更是千百倍的提高了人类的生产力,让社会物质极大的丰富,生活水平和生活质量都有了巨大的进步。

信息技术
计算机和互联网的发明给人类带来的改变,是人类历史上绝无仅有的,它们的出现使得人类在科学、文化等领域进入空前发展的阶段,同样也让全人类的沟通协作变得通畅无阻。
告警其实也是一种熵
我们把IT系统环境初始化的状态假设成是一个封闭状态,如果此时没有任何外界的能量变化例如:停电、断网,或者是任何来自外部的输入输出(例如:系统访问量等)变化时,我们有理由认为此时的环境将一直会是个稳定状态。
但是,当外界因素发生变化时,这个系统就会因改变状态而产生熵,熵多则代表产生的新状态多,可能性表现增多,系统将趋向混乱。产生的熵少则代表产生的新状态少,可能性表现较少,系统趋向稳定,相对来说就比较有秩序。可以说状态变化会让系统的混乱度增加,熵此时可以用来描述系统的混乱度,在系统里可以表现为告警的数量。

(图片来自:比特流技术)
在复杂的IT环境中,这个影响系统的外界因素是成倍数在增加的。而传统的监控工具并不是为了处理在高动态、复杂网络规模的企业云中运行的应用程序所产生的大量、快速和多样化的数据而设计的,这些工具通常是孤立的,缺乏对整个技术栈中发生的事件的更广泛的了解。因此,它们才会每天向IT团队发出数百甚至数千条警报。
不处理熵会怎样?
在热力学系统里转换的能量越大,创造出来的新状态就会越多,所以高能量系统不如低能量的系统来得稳定,高压锅不如普通锅安全就是这个道理。
热力学第二定律告诉我们,如果任由产生熵的系统自行运行下去最终都会趋向混乱度最大的状态,除非外部注入能量来处理熵。延伸到生活中来,熵的存在可以证明,如果不施加外力影响,事物永远向着更混乱的状态发展。比如,房间如果没人打扫,只会越来越乱,不可能越来越干净。

(图片来自互联网用户分享)
这只是房间的干净与否问题,如果换成前边说的高压锅,在加热过程中泄压阀坏了且你还不知道的情况下又会发生什么?
换到信息系统也一样,有着高并发高访问,复杂的架构、技术栈或代码逻辑特点的系统越容易出现问题。这些问题会由我们的监控工具“发现”,然后转换成告警发给IT人员,如果关键问题的告警没有被及时处理,那结果可能就是系统最后崩溃掉……
我们迫切需要新的手段来帮助自己应对这种复杂的情况。
AI可以帮我们处理告警这种熵
多源混合环境的数据自动整合
对来自不同平台,不同资源的告警能够进行数据的自动整合,并以统一的报表形式进行展现,这能够使用户不再受限于不同数据格式带来的可观测性障碍。

基于机器学习技术的场景化告警触发
在人工智能的帮助下,数据会在展示给用户之前进行预处理和初步分析——去除原始数据中通常会出现的噪音和混乱。AI识别的不再是发生的特定的单个事件或一系列事件,而是故障或攻击的整体模式。神经网络可以了解 IT 基础设施是如何适应日常工作的,不是发现恶意活动的迹象,而是确保操作可以检测到系统内的异常,这实质上使其与基于固定触发规则的系统完全相反。

聚合以避免告警风暴及告警疲劳
AI能够帮助我们对警报事件进行聚类形成故障,确定其严重性和影响并决定是否应将一个或多个故障上报以供IT人员处理。这个过程目前在许多企业中都是手动完成的,这在不久的将来会变成是一种不可接受的方法。
此种方式能够避免因海量不准确告警带来的风暴效应,进而避免因告警准确度低及数量庞大带来的告警疲劳。

总结
任何伟大的技术都是有它的双面性,AI的出现从大的范围看解决的或许是人类做为生物体的局限性,包括疾病、衰老、死亡。智能化的机器将不再存在实际中的生产力上限,甚至于思考能力的上限。
借助于它们的力量人类将第一次无限接近于神,我知道这听起来有些可怕,但这很可能成为事实。就如以色列学者尤瓦尔·赫拉利在《未来简史》一书中的感叹:
“包括人工智能在内的现代科技已经让人类拥有了超过远古诸神的力量,我们的后代势必将会拥有神一样的创造力和毁灭力。”
话扯远了,总结下来使用AI来提升处理告警的能力可以说是百利而无一害的,也是值得每一个企业应该大胆去尝试的方案。






